코드는 한 번 쓰고 끝나지 않는다. 내가 오늘 작성한 코드는 며칠 뒤의 나, 옆자리 동료, 새로 합류한 사람이 계속 다시 읽는다. 그래서 “일단 돌아간다”는 기준만으로는 부족하다. 읽는 사람이 의도를 빠르게 파악하고, 안전하게 고칠 수 있어야 좋은 코드에 가깝다.
기계가 이해하는 코드는 어떻게든 만들 수 있다. 어려운 부분은 사람이 이해할 수 있는 구조로 정리하는 일이다. 함수 이름, 책임의 경계, 호출 순서, 반환값의 의미가 분명해야 수정할 때 추측이 줄어든다.
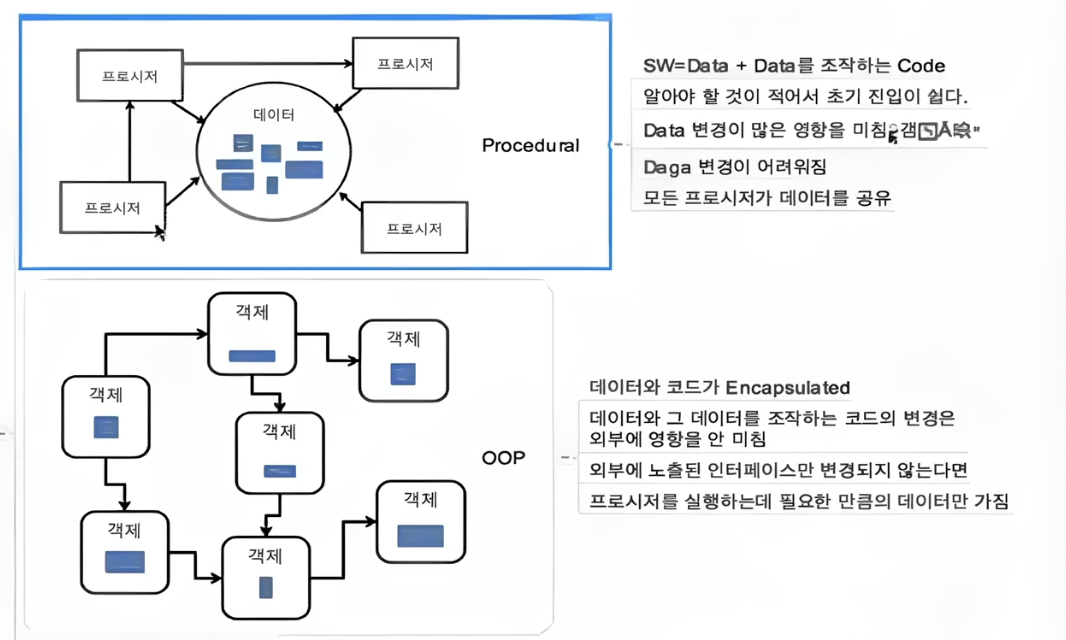
처음 코드를 짜면 보통 절차적으로 흐르기 쉽다. 위에서 아래로 처리 과정을 나열하는 방식이 가장 익숙하기 때문이다. 하지만 규모가 커지면 단순한 절차 나열만으로는 변경 지점을 찾기 어려워진다. 객체지향이나 함수 분리는 멋을 내기 위한 형식이 아니라, 변경되는 이유를 나누기 위한 도구로 봐야 한다.
읽기 쉬운 코드를 볼 때의 기준
먼저 중요한 흐름이 위에서 잘 보이는지 본다. 공개 메서드나 핵심 함수가 먼저 나오고, 세부 구현은 아래로 내려가면 읽는 사람이 큰 그림을 잡기 쉽다. 관련해서 Function Stricitre처럼 함수 배치만 바꿔도 코드의 첫인상이 달라진다.
다음은 호출 순서에 대한 의존이다. 어떤 함수를 반드시 먼저 호출해야만 다른 함수가 정상 동작한다면, 그 순서를 코드가 강제하는지 확인해야 한다. 그렇지 않으면 사용하는 사람이 실수하기 쉽다. 이런 문제는 Temporal Coupling에서 따로 정리한다.
상태를 바꾸는 동작과 값을 조회하는 동작도 섞이지 않는 편이 좋다. 조회하는 줄 알았는데 내부 상태가 바뀌면 디버깅이 어려워진다. 이 기준은 CQS로 이어진다.
클린 코드는 규칙을 많이 외우는 문제가 아니다. 코드를 읽는 사람이 덜 추측하게 만드는 선택을 반복하는 일이다. 세부 원칙은 클린코드 핵심원칙 구조에서 이어서 정리한다.